The Page Indexing Report in Google Search Console is an essential tool for webmasters and SEO professionals. It provides insights into how Googlebot interacts with your website’s pages, highlighting which pages are indexed, which are not, and the reasons behind these statuses.
Common errors in page indexing
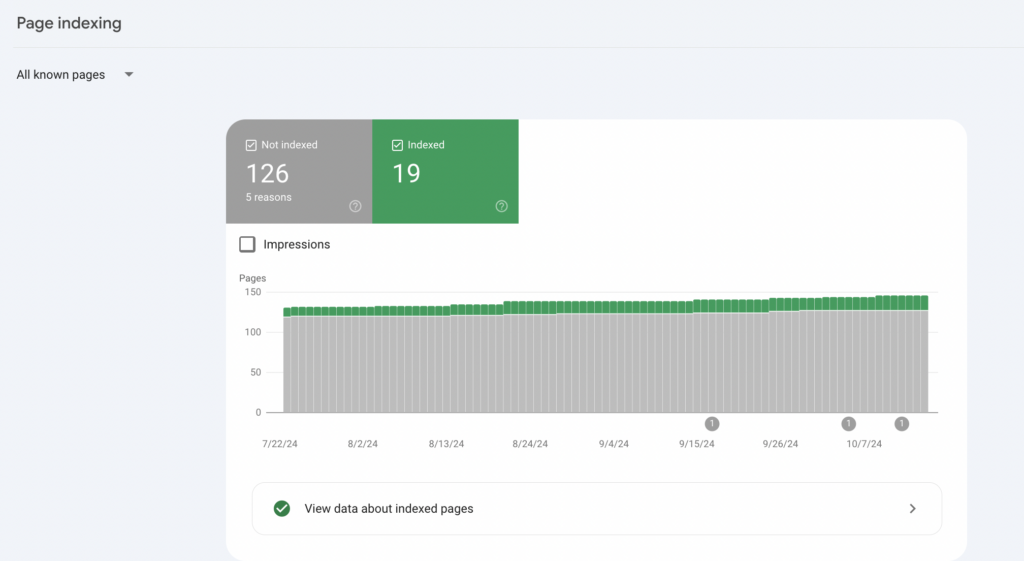
Not indexed
In Google Search Console you will find 2 sections – one with indexed URLs, the other with non-indexed URLs. Below we will focus only on those that have not indexed status.
Please note that pages that have not been indexed do not necessarily contain errors. It is very important that you read the detailed descriptions provided to determine whether action is needed.
Server Error (5xx)
A 500-level error indicates a server issue when Google attempts to access the page. This needs immediate attention to ensure proper functionality.
Read the article dedicated to Server errors (5xx).
Redirect errors
These can occur due to:
– Long redirect chains
– Redirect loops
– URLs exceeding maximum length
– Bad or empty URLs in the redirect chain
Tools like Lighthouse can help diagnose these issues.
See our guide about Redirect errors.
URL blocked by robots.txt
If a page is blocked by your site’s `robots.txt` file, it won’t be crawled by Googlebot. However, it may still be indexed if linked elsewhere (and that’s how Google finds out about it).
See our guide about URL blocked by robots.txt
URL marked ‘noindex’
Pages with a ‘noindex’ directive will not be indexed. If indexing is desired, this directive must be removed.
Soft 404
This occurs when a page returns a user-friendly “not found” message without a proper 404 HTTP response code. Correctly returning a 404 status for non-existent pages is recommended.
Blocked due to unauthorized request (401)
If access requires authorization, Googlebot will be unable to index the page unless access is granted.
Not found (404)
If a page returns a 404 error, it indicates that the page does not exist. Google may continue to attempt crawling this URL over time.
Blocked due to access forbidden (403)
This error indicates that Googlebot was denied access due to incorrect server settings.
Crawled – currently not indexed
Pages that have been crawled but not indexed may still be considered for future indexing.
Duplicate content issues
Duplicate without user-selected canonical
Indicates that Google has chosen another URL as canonical.
Duplicate, Google chose different canonical than user
The user-declared canonical is not the one selected by Google.
Page with redirect
Non-canonical URLs that redirect will not be indexed unless the target URL is indexed.
Warnings in page indexing
Warnings do not prevent indexing but indicate potential issues. In GSC you will encounter the following warnings:
H3: Indexed, though blocked by robots.txt
The page may still appear in search results despite being blocked.
Page indexed without content
Indicates that Google could not read the content of the page, possibly due to cloaking or unsupported formats.
Read more about Page indexed without content.
Understanding these errors and warnings allows you to take corrective actions effectively, ensuring that your website is fully optimized for search engines.
Citations:
https://support.google.com/webmasters/answer/7440203?hl=en